

A practical guide for enterprise architects, integration consultants, and security teams
1. Introduction
AI agents are no longer a research novelty. They are showing up inside enterprise workflows — reading tickets, querying HR systems, drafting responses, triggering approvals, and executing multi-step processes with minimal human involvement. The question organisations now face is not whether to deploy them, but how to ensure that AI agents securely interact with enterprise systems in ways that are auditable, controllable, and aligned with existing governance frameworks.
This article examines how that interaction works in practice: the protocols, identity models, permission structures, and failure modes that security and integration teams need to understand. It pays particular attention to the Model Context Protocol (MCP), an emerging open standard for connecting AI applications to tools and data sources, and explains clearly where MCP helps and — equally important — where it does not.
Note: This article reflects current public guidance as of mid-2025 and may evolve as standards mature. Where guidance is still forming, that is stated explicitly.
2. What AI Agents Do in Enterprise Systems
An AI agent, in the enterprise context, is a software component that uses a large language model (LLM) to reason about a goal and then takes actions to pursue it. Those actions typically involve calling external tools or APIs: querying a database, sending a message, reading a file, updating a record, or invoking a downstream service.
Unlike a traditional script, an agent can chain these calls together based on intermediate results. It can read an HR ticket, decide it needs payroll data, fetch it from a second system, cross-reference with an absence record in a third, and produce a summary — all without a human initiating each step.
This capability is genuinely useful. It is also the source of the security challenge. When a system can autonomously decide which tools to invoke and what data to retrieve, the attack surface expands considerably. The relevant question is not just “what can this agent do?” but “what has it been authorised to do, by whom, under what conditions, and with what audit trail?”
How agents call tools
Most LLM frameworks implement tool calling through a structured mechanism: the model receives a list of available tools (described as functions with names, parameters, and descriptions), and when it decides to use one, it outputs a structured call rather than plain text. The host application intercepts that call, executes it, returns the result to the model, and the model continues reasoning.
This means the LLM itself never directly executes code or calls APIs. The host application does. That distinction matters for security: the controls that matter are in the host layer, not inside the model.
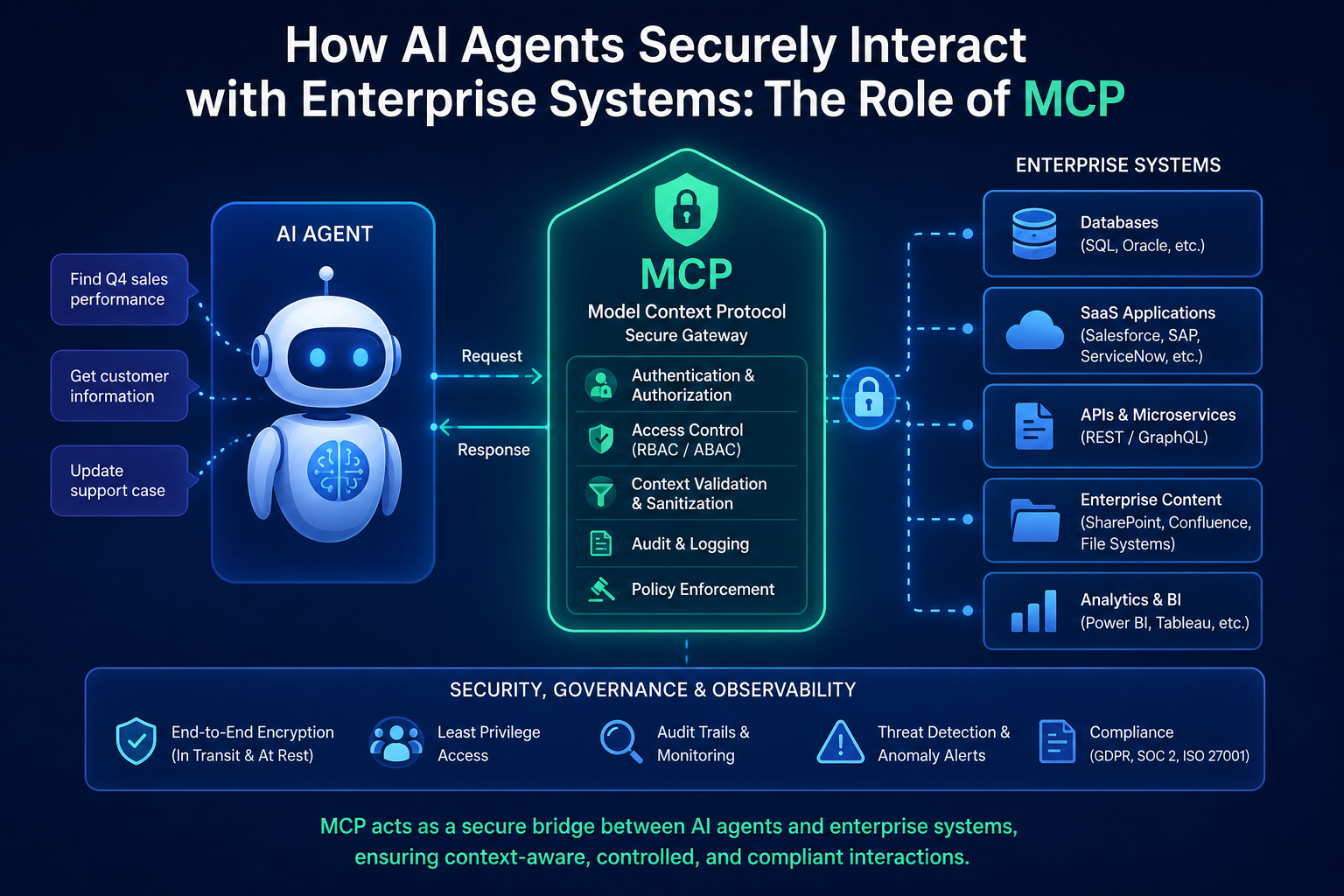
3. What MCP Is and Where It Fits
The Model Context Protocol (MCP) is an open protocol published by Anthropic in late 2024. Its stated purpose is to provide a standard way for AI applications to connect to tools, data sources, and services — reducing the integration work that would otherwise require a custom connector for every combination of LLM framework and enterprise system.
MCP defines a client-server architecture. An MCP client (typically the AI application or agent host) connects to one or more MCP servers. Each server exposes a set of capabilities — tools, resources, and prompts — that the client can discover and invoke. The protocol specifies how these are described, negotiated, and called.
In practical terms, this means an organisation can build or deploy an MCP server that wraps, say, its HR system API, and any MCP-compatible AI application can then use that server without needing a bespoke integration layer. The value is in standardisation and interoperability.
What MCP is not
MCP is a communication and interoperability protocol. It is not a security model. The specification does not define how an agent should be authenticated to an MCP server, how permissions should be scoped, how audit logs should be generated, or how sensitive actions should be gated. These decisions are left to the implementer.
This is by design: protocol standards typically separate the transport and interface layer from the security layer. The practical consequence is that an MCP deployment without enterprise security controls layered on top is not inherently secure. The protocol makes integration easier; it does not make it safe by default.
The MCP specification is evolving. As of mid-2025, work on authentication and authorisation within MCP — including OAuth 2.0-based patterns — is active but not fully standardised across all implementations. Organisations should consult the official MCP documentation and their vendors for the current state.
4. Security Controls That Matter
The following eight areas represent the controls that enterprise teams need to address when deploying AI agents that interact with business systems. They are not MCP-specific; they apply regardless of the integration layer used. But they become especially critical in agentic architectures because agents can chain actions autonomously.
4.1 Identity and Authentication for Agents
Every agent that interacts with enterprise systems needs an identity. That identity should be distinct from the human user who initiated the agent session, and it should be distinct from the service account of the host application itself.
NIST SP 800-207 (Zero Trust Architecture) and the broader NIST identity guidance recommend treating non-human identities — including automated agents — as principals that require the same rigour as human identities: strong authentication, regular credential rotation, and revocability.
In practice, this means assigning agents dedicated service principals or workload identities (using mechanisms like OAuth 2.0 client credentials, SPIFFE/SPIRE workload identity, or cloud provider IAM roles). Shared credentials between agents and other systems should be avoided.
4.2 Least Privilege and Scoped Permissions
An agent should be authorised to do only what the current task requires, and no more. This is the principle of least privilege, a foundational concept in NIST SP 800-53 and the CIS Controls.
For AI agents, this has two dimensions. First, the agent’s service identity should hold only the permissions the system requires across all tasks. Second, where possible, permissions should be further scoped to the current session or action — so an agent that needs to read an employee record should not simultaneously hold write access to payroll.
MCP server implementations can support this by exposing tools at a granular level and allowing the calling application to invoke only those tools it has been granted access to. But the enforcement of that access boundary sits outside MCP, in the authorisation layer.
4.3 Short-Lived Credentials and Token Exchange
Long-lived credentials are a persistent risk in any integration architecture. In agentic systems, they are especially problematic because a compromised agent credential could be reused across many sessions before detection.
The preferred approach, consistent with OAuth 2.0 guidance and cloud security best practices, is to use short-lived tokens that are issued for a specific session, expire quickly, and are obtained through a token exchange or authorisation flow at session start. If the agent is operating on behalf of a specific user, impersonation or delegated access flows (such as OAuth 2.0 token exchange as defined in RFC 8693) can scope the credential to that user’s permissions for the duration of the task.
This limits the blast radius if a credential is leaked or a session is hijacked.
4.4 Human Approval for Sensitive Actions
Not all agent actions should execute automatically. Certain actions — deleting records, sending external communications, modifying access permissions, approving financial transactions — warrant a human review step before execution.
This is sometimes called a “human-in-the-loop” control. The agent prepares the action and presents it for approval; execution is gated on human confirmation. This pattern is particularly important during early deployment when the agent’s behaviour is still being validated, and for irreversible or high-impact operations.
Implementing this requires the host application to categorise actions by risk level and route high-risk ones to an approval queue. It is an architectural decision, not something MCP or the LLM itself enforces.
4.5 Logging, Traceability, and Audit Trails
Every action an agent takes should be logged with enough context to reconstruct what happened, why it happened, and under whose authority. This is a basic requirement for incident response, regulatory compliance, and ongoing governance.
A useful audit record for an agent action includes: a timestamp, the agent identity, the initiating user (if applicable), the tool or API called, the parameters supplied, the result returned, and the session or workflow identifier. NIST SP 800-92 provides guidance on log management that applies here.
In MCP deployments, logging should occur at the MCP server level (recording which tools were invoked with which inputs) and at the host application level (recording the agent’s reasoning chain and decisions). Relying on only one layer creates blind spots.
4.6 Prompt Injection and Tool Misuse Defences
Prompt injection is one of the most practically relevant threats to AI agents in enterprise environments. OWASP’s LLM Top 10 (published in 2023 and updated subsequently) lists prompt injection as the top risk for LLM applications.
In an agentic context, the attack vector is broader than simple chatbot manipulation. An agent that reads emails, documents, or web pages can be fed malicious instructions embedded in that content — instructions designed to redirect the agent’s behaviour, exfiltrate data, or invoke unintended tools. This is sometimes called indirect prompt injection.
Defences include: treating all externally sourced content as untrusted input, not as instructions; restricting the tools available to an agent to only those needed for the current task (reducing the impact of a successful injection); enforcing output validation before acting on model-generated parameters; and applying anomaly detection to tool call patterns.
There is no complete technical solution to prompt injection at the LLM layer as of mid-2025. Defence in depth at the application and tool layer is the practical approach.
4.7 Supply-Chain Security for MCP Servers and Tools
An MCP server is a piece of software. It can be built in-house, sourced from a vendor, or pulled from an open-source registry. Each of these represents a supply-chain risk that is not fundamentally different from the risks in any software dependency, but the context amplifies the stakes: a compromised MCP server can intercept agent inputs, manipulate tool outputs, or exfiltrate data passed through it.
NIST SP 800-161 (Cybersecurity Supply Chain Risk Management) provides a framework for assessing these risks. In practice, this means: vetting third-party MCP server publishers, reviewing server code before deployment (especially for servers with access to sensitive systems), pinning server versions to avoid silent updates, and monitoring server behaviour at runtime.
The concept of “tool poisoning” — where a malicious tool description misleads the LLM about the tool’s behaviour — is an active area of research. Organisations should not assume that a tool is safe simply because it appears in an MCP server they trust.
4.8 Isolation and Sandboxing for Risky Execution Paths
Agents that execute code, run shell commands, or interact with file systems require stronger isolation than agents that only call read-only APIs. The principle here is containment: if an agent is compromised or behaves unexpectedly, the impact should be bounded.
Containerisation (using tools like Docker or Kubernetes with appropriate security policies), network segmentation, and read-only file system mounts are practical mitigations. For agents that write code and execute it, sandboxed execution environments with resource limits and no outbound network access are appropriate.
This is consistent with the defence-in-depth principle and applies regardless of whether MCP is involved.
5. Risks, Failure Modes, and Common Mistakes
Understanding how these systems fail in practice is as important as knowing the correct controls. The following are failure modes observed in early enterprise AI deployments and in published security research.
Over-permissioned agent identities
Agents are often granted broad permissions during development to reduce friction, and those permissions are not tightened before production. An agent with read-write access to a production database when it only needs read access is a significant and unnecessary risk. Least privilege should be enforced at the point of deployment, not left as a post-launch task.
Treating MCP as a security boundary
A common mistake is assuming that because an MCP server sits in front of an enterprise system, it provides a security layer. It does not. Unless the MCP server explicitly enforces authentication, authorisation, and input validation, it is a pass-through. An unauthenticated MCP server that wraps a privileged API is worse than no MCP server at all, because it may create a false sense of security.
Inadequate logging of agent reasoning
Many implementations log API calls but not the agent’s reasoning chain. When something goes wrong, it is difficult to reconstruct why the agent made a particular decision without that context. Logging should capture the model’s inputs and tool call decisions, not just the downstream API traffic.
No rollback or undo for agent actions
Agents operating on mutable systems can cause hard-to-reverse changes. Organisations should design agent workflows with reversibility in mind: prefer soft deletes over hard deletes, maintain change logs, and implement confirmation steps before destructive operations.
Accepting third-party MCP servers without review
The growing ecosystem of community-built MCP servers is a productivity accelerator but also a risk surface. Servers published by unknown authors, with broad access scopes and no transparent code review, should be treated with the same caution as any unvetted third-party library in a production system.
Skipping human-in-the-loop for “low-risk” actions
Risk assessments made at design time often underestimate the blast radius of errors in production. Teams that skip human approval for “low-risk” actions sometimes discover that those actions, when chained together incorrectly by the agent, produce high-impact outcomes. Conservative risk classification during early deployment is advisable.
6. Enterprise Implementation Checklist
The following checklist is intended for integration architects and security teams deploying AI agents in enterprise environments. It is not exhaustive but covers the most critical decisions.
| Category | Required Action |
| Identity | Assign dedicated workload identities to each agent type. Do not reuse human or shared service credentials. |
| Authentication | Use strong, short-lived credentials. Implement token exchange for user-delegated sessions. |
| Authorisation | Define and enforce least-privilege permission scopes per agent role. Review scopes before production. |
| MCP Servers | Vet all MCP servers (internal and third-party). Pin versions. Review code for servers with access to sensitive systems. |
| Tool Scoping | Expose only the tools required for each agent’s task. Restrict tool availability per session where possible. |
| Logging | Log all tool calls with inputs, outputs, agent identity, and session ID. Log agent reasoning where feasible. |
| Human Gates | Classify actions by risk level. Route high-risk and irreversible actions to a human approval queue. |
| Prompt Injection | Treat all externally sourced content as untrusted. Validate tool call parameters before execution. |
| Sandboxing | Isolate agents that execute code or access file systems. Apply network segmentation and resource limits. |
| Monitoring | Implement anomaly detection on tool call patterns. Alert on unusual access volumes or out-of-scope calls. |
| Governance | Define ownership for each agent deployment. Establish a review cadence for permissions and behaviour. |
| Rollback | Design workflows with reversibility. Prefer soft operations and maintain change logs for agent-driven modifications. |
7. Conclusion
Getting AI agents to securely interact with enterprise systems is achievable, but it requires deliberate work. The Model Context Protocol offers a useful standardisation layer that can reduce integration complexity and improve interoperability between AI applications and enterprise tools. That is a real benefit, particularly for teams managing multiple systems.
But MCP is a protocol, not a security product. The controls that make agentic deployments trustworthy — identity management, scoped permissions, short-lived credentials, human approval gates, audit logging, injection defences, supply-chain hygiene, and sandboxing — sit in the implementation layer. They require explicit design choices and ongoing governance.
The organisations most likely to deploy AI agents safely are those that treat agents as first-class principals in their identity and access management frameworks, build logging and observability in from the start, and resist the temptation to move faster than their security controls can keep up with. The technology is moving quickly. The fundamentals of identity, least privilege, and auditability are not.
Suggested Internal Links
1. Anchor: “Enterprise API security best practices” → Link to your API governance or security standards article
2. Anchor: “How to implement zero trust for non-human identities” → Link to your identity architecture guide
3. Anchor: “AI governance frameworks for enterprise” → Link to your AI policy or governance page
4. Anchor: “HRMS integration security considerations” → Link to your HR systems integration guide
5. Anchor: “Audit logging requirements for automated systems” → Link to your compliance and logging standards article
Suggested External Links
1. Anchor: “OWASP LLM Top 10” → https://owasp.org/www-project-top-10-for-large-language-model-applications/
2. Anchor: “NIST SP 800-207 Zero Trust Architecture” → https://csrc.nist.gov/publications/detail/sp/800-207/final
3. Anchor: “Model Context Protocol official documentation” → https://modelcontextprotocol.io/
4. Anchor: “NIST SP 800-161 Supply Chain Risk Management” → https://csrc.nist.gov/publications/detail/sp/800-161/rev-1/final
5. Anchor: “RFC 8693 OAuth 2.0 Token Exchange” → https://datatracker.ietf.org/doc/html/rfc8693



